ACL 2023 Oral Paper | ManagerTower: 自适应融合单模态专家见解的视觉语言表示学习方法
ManagerTower: Aggregating the Insights of Uni-Modal Experts for Vision-Language Representation Learning
Xiao Xu, Bei Li, Chenfei Wu, Shao-Yen Tseng, Anahita Bhiwandiwalla, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
ACL 2023 (Oral) | Association for Computational Linguistics
Paper | Arxiv | Code | Slides | Video(EN) | Video(CN) | Blog(CN) | Tweet(EN)
0. Take-away messages¶
- 提出了一个简单有效的视觉语言模型架构,ManagerTower,通过在每个跨模态层中引入Manager,从而自适应地聚合不同层次的预训练单模态专家的Insight,针对不同样本中的不同令牌,灵活地生成不同的聚合权重,促进更全面的跨模态对齐和融合。
- 通过交叉注意力机制融合之前跨模态层的输出表示,从而得到跨模态融合查询,进一步帮助Manager正确聚合当前跨模态层所需的单模态语义知识。
- 在公平的评估设置下,与Two-Tower架构的METER模型以及BridgeTower架构相比,ManagerTower显著地提高了模型的多模态表示能力。
- 仅使用400万张图片进行视觉语言预训练,ManagerTower在各种视觉语言下游任务上取得了十分强大的性能,击败了许多用更多数据和参数进行预训练的强大模型。
- ManagerTower可以适用于不同的视觉、文本或跨模态编码器。
1. 背景与动机¶

图源:12-in-1: Multi-Task Vision and Language Representation Learning
视觉语言研究的目标,是训练一个能够理解图像和文本的智能AI系统。 上图展示了一些流行的视觉语言任务。视觉问答是其中最著名的任务之一,它需要根据输入图像来回答和图片相关的问题。
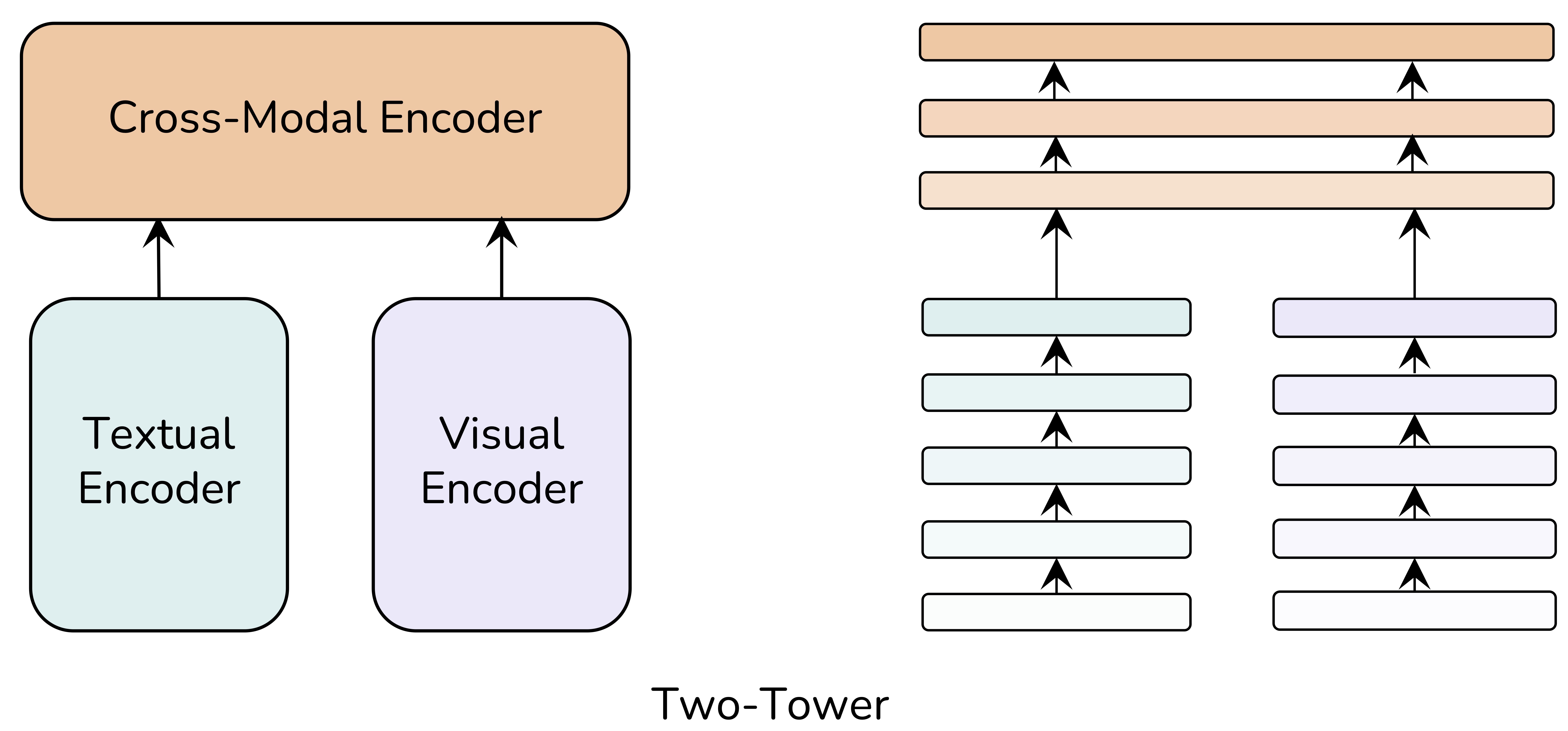
自2019年以来,在大规模图像-文本对的自监督预训练的帮助下,基于Transformer的视觉语言模型取得了显著的进展。 从模型架构的角度来看,近期工作可以看作是由三个模块组成的双塔架构,即文本编码器、视觉编码器,以及在它们之上的跨模态编码器。 如果我们深入双塔结构的单模态编码器中,例如METER模型。 我们可以发现他们只将最后一层的单模态特征直接送入顶部的跨模态编码器,忽略了深层单模态编码器中不同层次的语义信息。
不同于双塔结构,BridgeTower将多个顶部单模态层与每个跨模态层逐层连接,以利用不同层次的单模态语义知识。
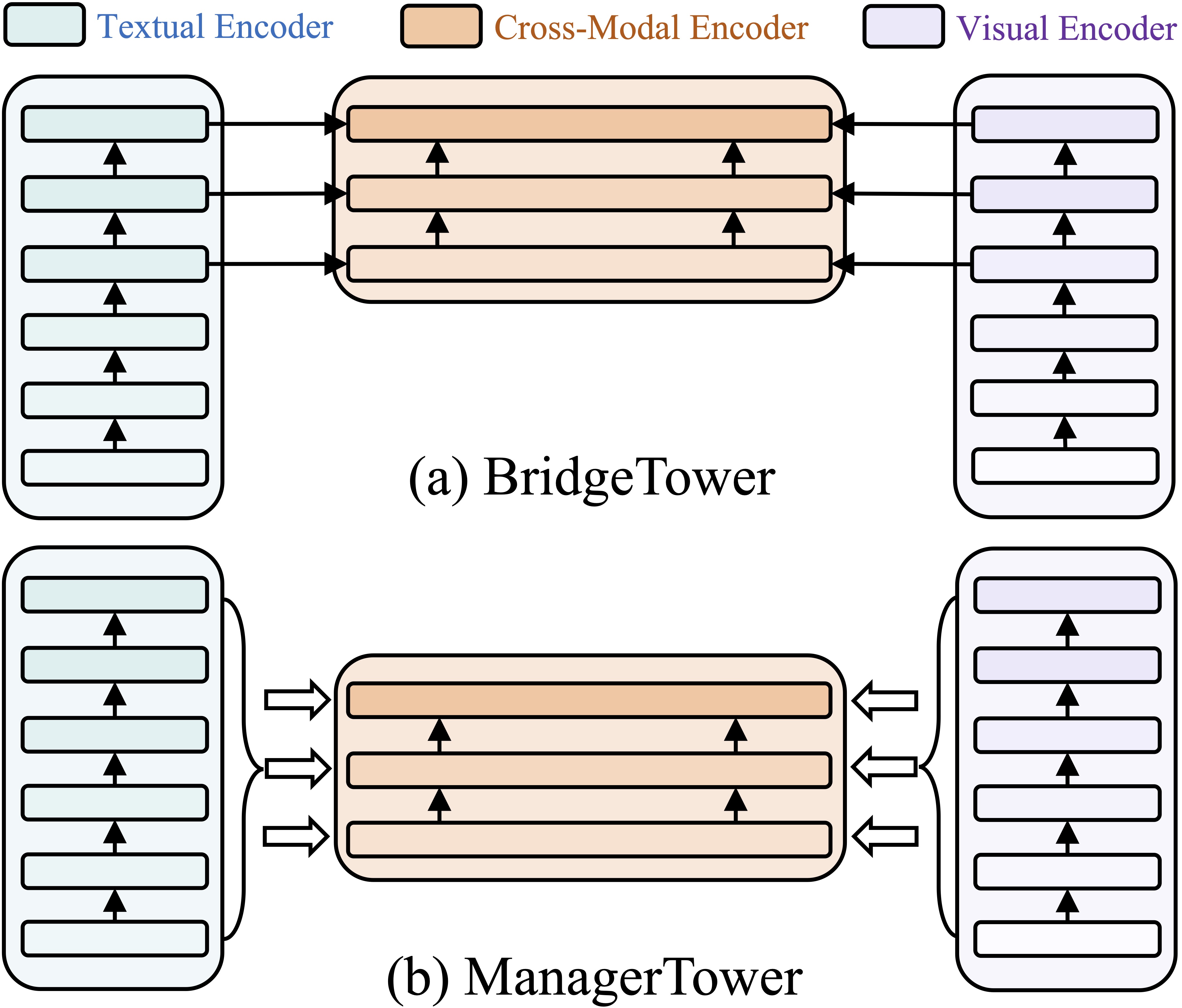
但是 BridgeTower 仍然存在两个显著缺陷,限制了它对单模态表示的高效利用。
- 首先,它对不同单模态层表示的逐层利用是低效的。每个跨模态层只能利用人为指定的某一单模态层表示,因此限制了其对不同层次的单模态语义知识的利用。
- 其次,跨模态层的数量与它所使用的单模态层表示的数量是绑定在一起的,因此限制了其可扩展性和能力。
我们在BridgeTower的基础上,对以上两个方面加以改进,并提出了名为ManagerTower的新颖的VL模型架构。 每个Manager(管理者)将多层单模态表示视为不同层次的预训练单模态专家的Insight(洞察力)。 ManagerTower能够通过每个跨模态层的Manager自适应地聚合Insight。
2. 模型架构¶
这里我们展示了ManagerTower的详细架构图。 具体而言,我们使用RoBERTa Base和CLIP-ViT Base作为单模态编码器。 跨模态编码器为6层,在每个跨模态层中引入了Manager,以聚合不同层次的预训练单模态专家的Insight。
Manager可以自适应地利用不同层次的单模态语义知识,,针对不同样本中的不同令牌,灵活地生成不同的聚合权重,促进更全面的跨模态对齐和融合。 需要注意的是,ManagerTower架构适用于不同的视觉、文本或跨模态编码器。
3. Manager 的设计¶
3.1 静态聚合专家的 SAE Manager¶
在Layer Fusion(层融合)方法的启发下,我们采用并调整了层线性组合的方法,通过可学习的权重将之前所有的单模态和跨模态层表示聚合起来。

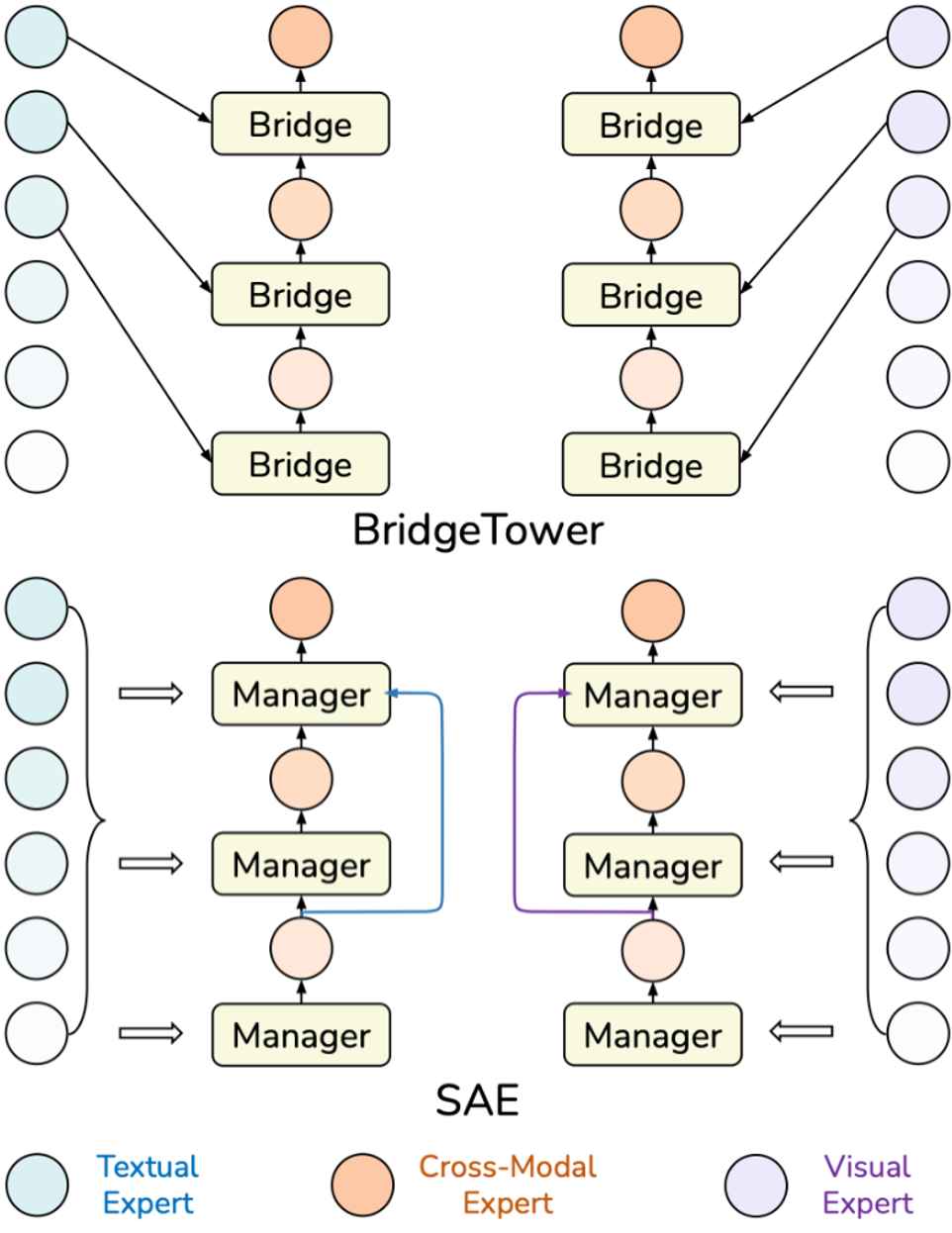
我们称之为静态聚合专家的SAE Manager。 上图简要地显示了BridgeTower和SAE Manager的计算流程以及结构对比。 这里的 \(\ell\) 表示跨模态层的编号。然而,与BridgeTower相比,其性能增益仍然是有限的。
接着我们计算每两个连续的文本/视觉Manager之间聚合的单模态/跨模态表示的余弦相似度,以进一步分析SAE Manager是如何聚合Insight的。
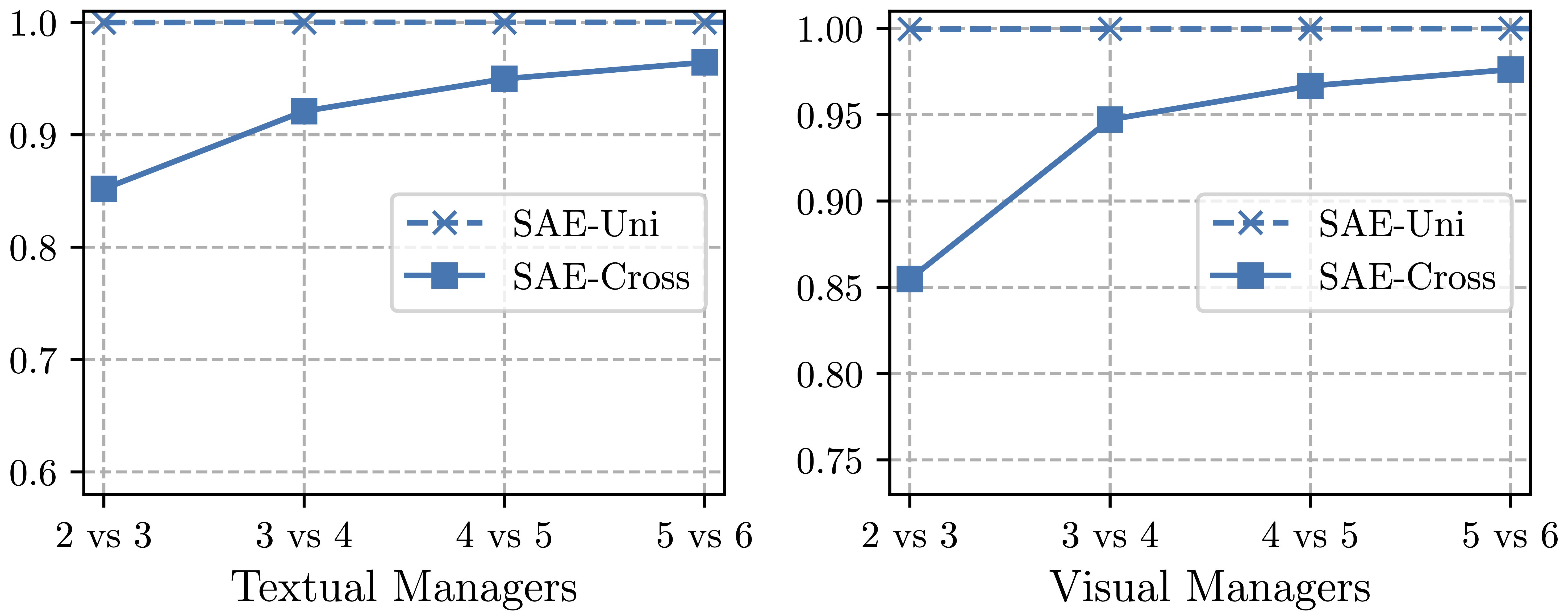
如上图所示,SAE的单模态聚合表示的相似度总是接近1,而跨模态的相似度随着深度的增加而增加,越来越接近于1。这表明,在不同的SAE Manager中,聚合的单模态表示几乎是相同的,而聚合的跨模态表示随着深度的增加而变得相似。
我们假设,由于不同的SAE Manager为每个跨模态层提供相似的聚合单模态表示,这使得更多的之前跨模态层的输出表示,可能会带来混淆Manager的过多冗余信息。 因此,我们认为应当聚焦于所有单模态层表示和前一个跨模态层表示。
3.2 静态聚合单模态专家的 SAUE Manager¶

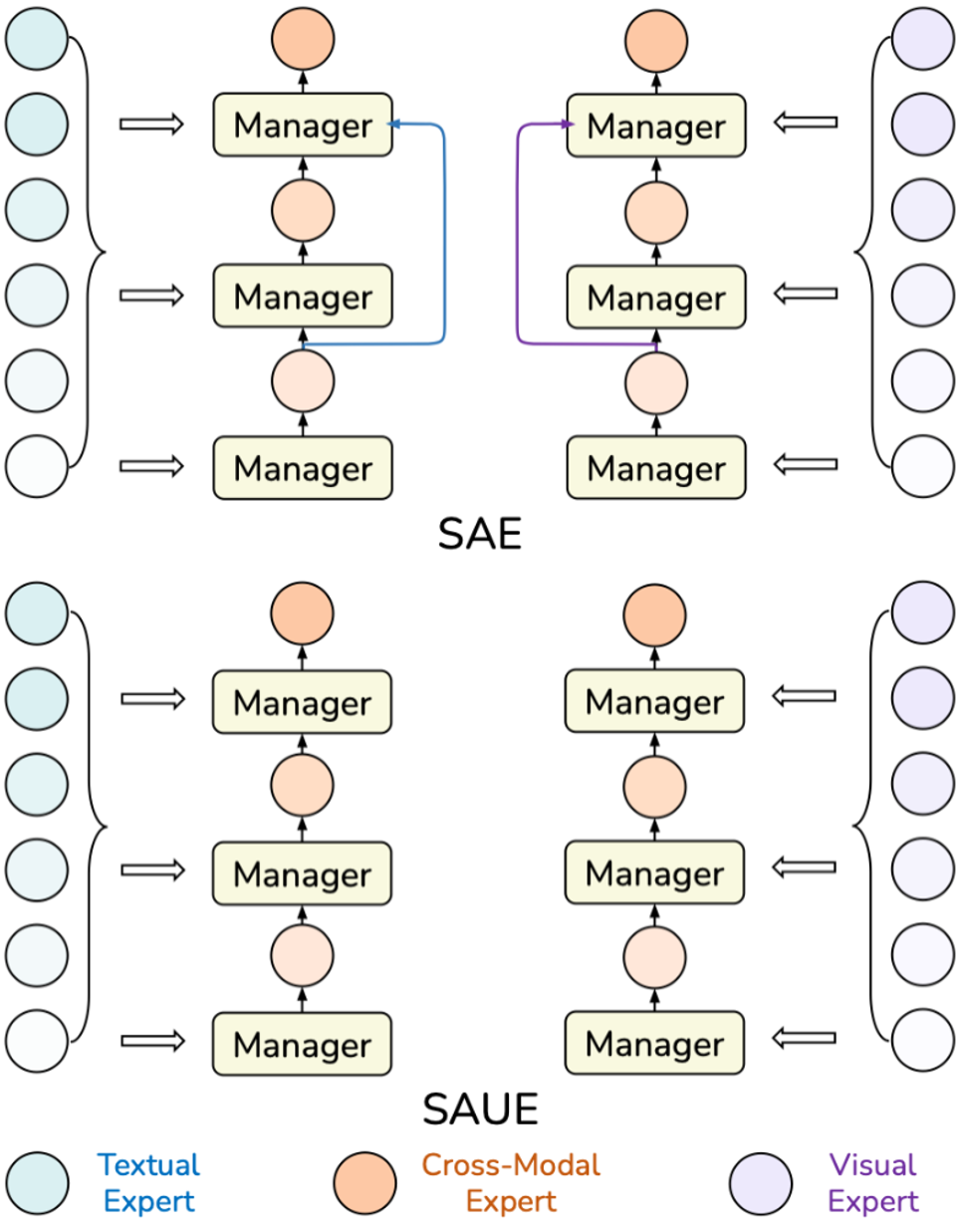
我们称之为静态聚合单模态专家的SAUE Manager。 上图简要地显示了SAE和SAUE Manager的计算流程以及结构对比。
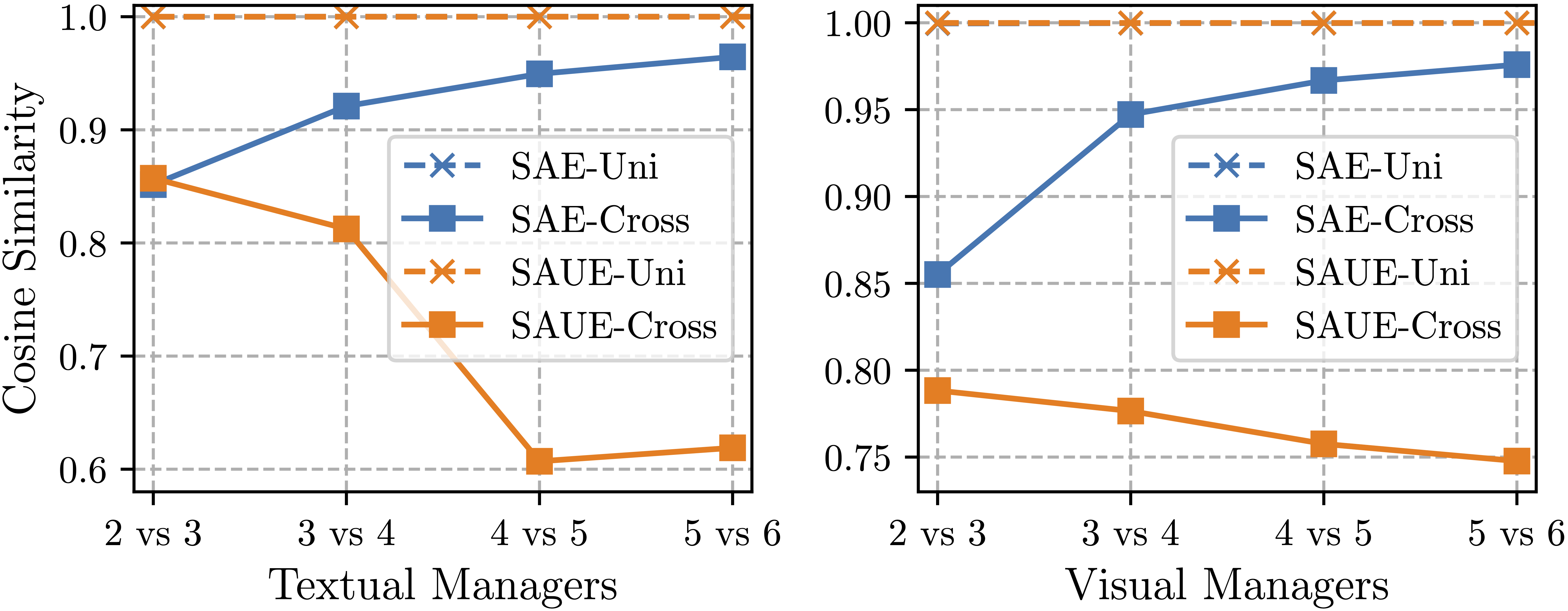
有趣的是,SAUE的跨模态聚合表示的相似度会随着深度的增加而降低。 这表明随着深度的增加,SAUE可以聚合得到更全面和可区分的跨模态表示。 与BridgeTower相比,明显改善的结果也进一步证明了我们的假设。
然而,SAUE仍然存在两个问题:
- 首先,聚合的单模态表示在不同的Manager之间仍然是几乎相同的,这与跨模态层之间对单模态语义知识的需求是不同的的直觉不一致;
- 第二,在推理阶段,Manager将训练阶段学到的相同权重应用于不同样本中的所有令牌,以聚合单模态专家的Insight,这与对单模态语义知识的需求在令牌之间以及样本之间是不同的的直觉不一致。
3.3 自适应聚合单模态专家的 AAUE Manager¶

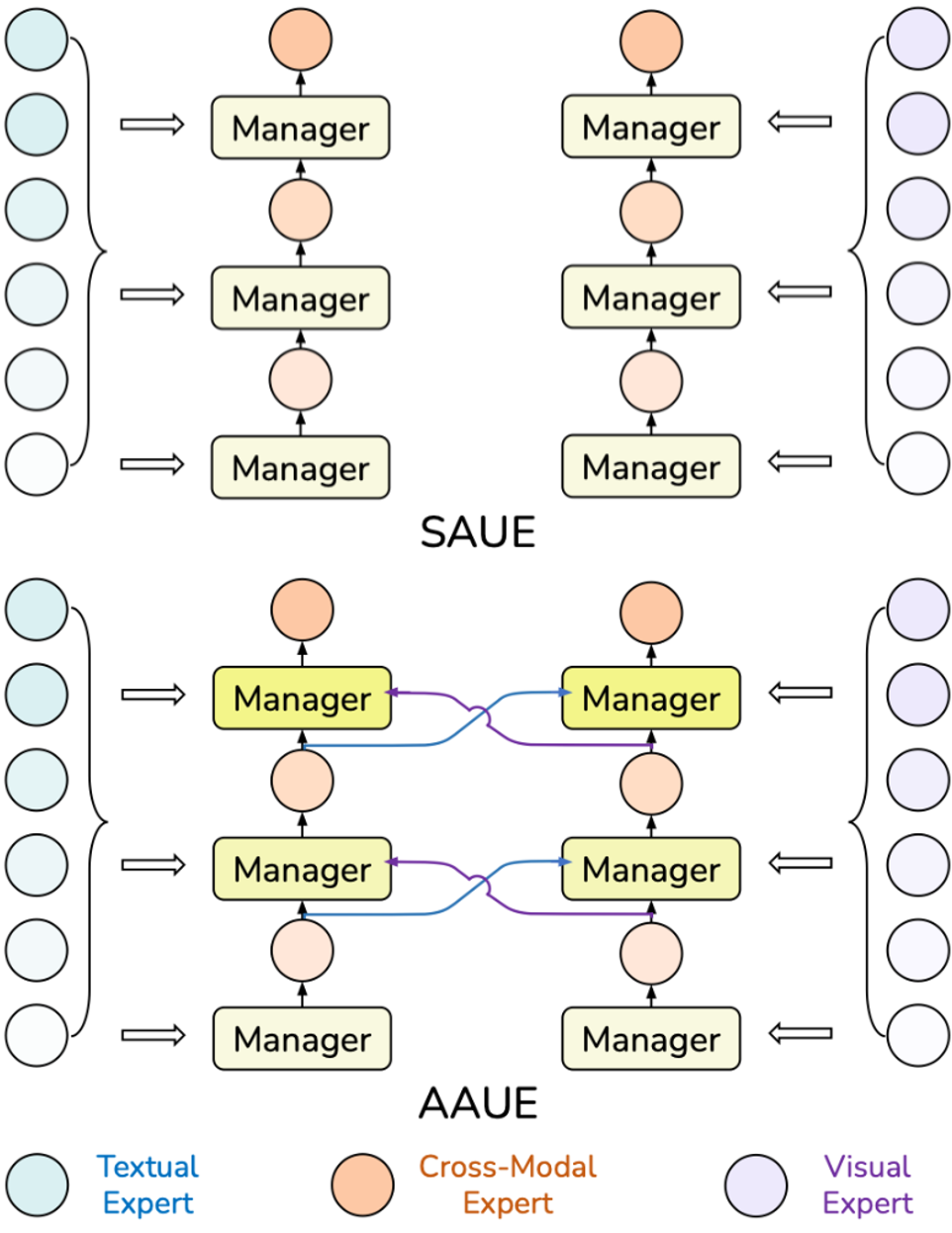
为了解决上述局限性,我们提出了自适应聚合单模态专家的AAUE Manager。 上图简要地显示了SAUE和AAUE Manager的计算流程以及结构对比。 AAUE将输入的跨模态部分作为视觉/文本查询(Query),从而生成聚合权重。
从聚合权重的角度来看:
- 之前的SAE和SAUE Manager是静态的句子级Manager,对不同样本中的所有令牌共享相同的、在训练阶段学习到的可聚合权重。
- 相比之下,AAUE Manager是自适应的令牌级Manager,它为不同样本中的不同令牌自适应地生成不同的聚合权重。因此,AAUE可以在训练和推理阶段自适应地利用预训练单模态专家的不同层次的单模态语义知识。
3.4 不同Manager的性能比较¶
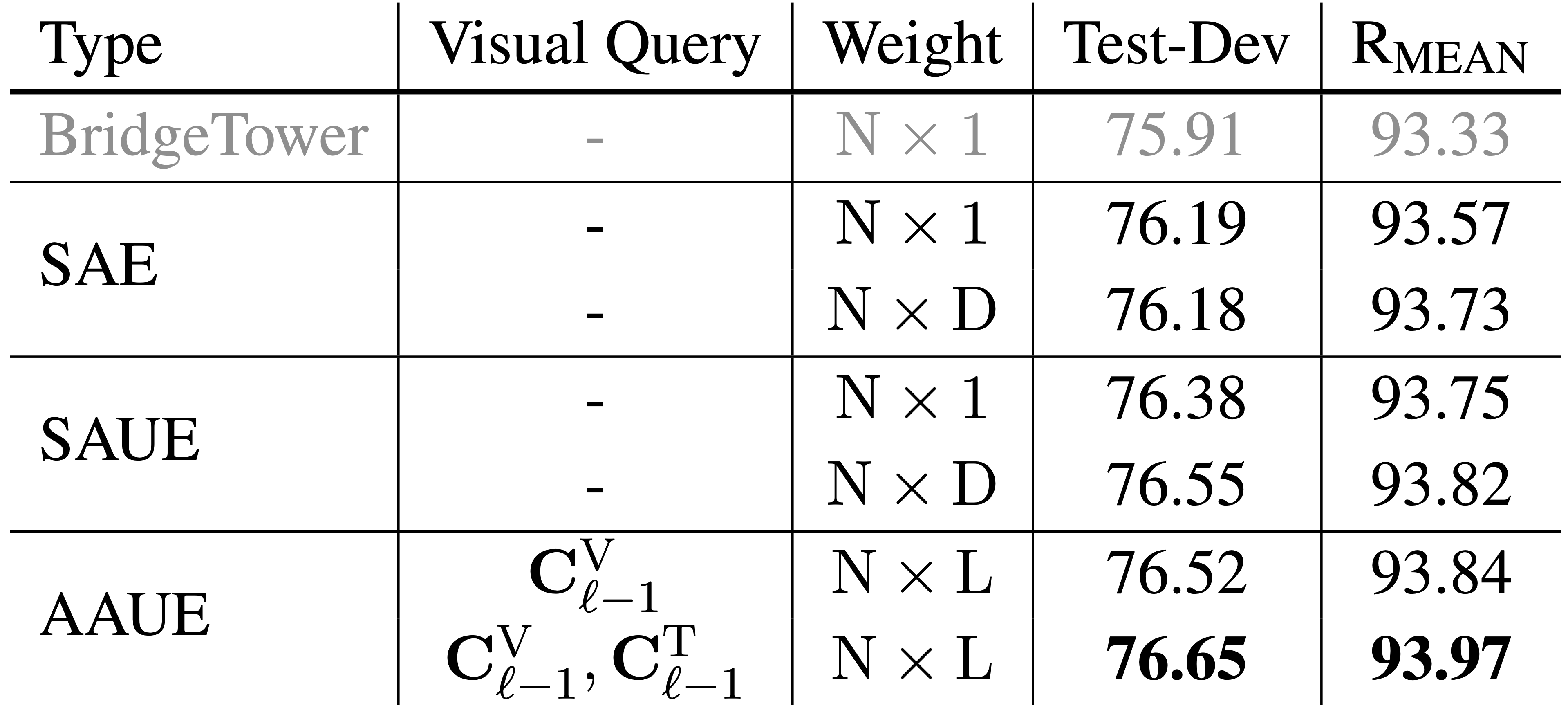
上表中显示了不同类型的Manager和不同Query在VQAv2和Flickr30K数据集上的表现。
为了帮助每个跨模态层的Manager更好地利用单模态的语义知识,我们使用Cross-Attention机制,来利用文本查询丰富视觉查询,从而得到跨模态的融合查询,这可以更好地帮助Manager正确地聚合当前跨模态层所需的单模态语义知识。 在跨模态融合查询的帮助下,AAUE Manager在两个数据集上都取得了大大优于其他Manager的性能。
4. 实验效果¶

我们基于公共图文对数据集对BridgeTower进行预训练,如上表所示,大约共计400万张独立图片,900万对图文对。 我们使用通用的掩码语言建模 (Masked Language Modeling, MLM) 和图文匹配 (Image-Text Matching, ITM) 任务作为预训练任务。 所有的预训练设置与预训练参数都与METER和BridgeTower一致,以提供ManagerTower与METER和BridgeTower之间的公平比较。
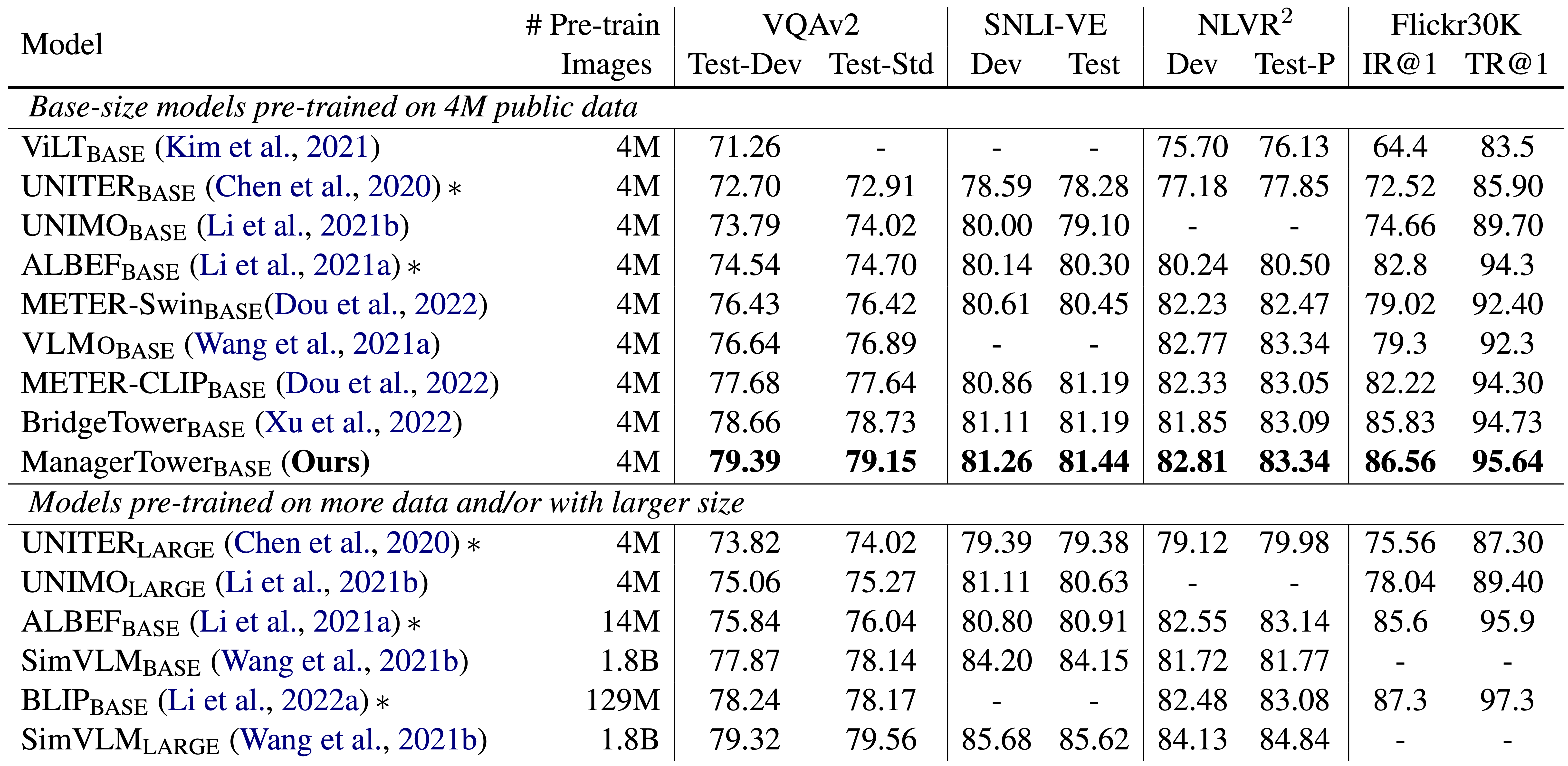
仅利用 400w 张独立图像进行视觉语言预训练,ManagerTower在各种下游的视觉语言任务上取得了卓越的表现。尤其是,METER、BridgeTower和ManagerTower使用相同的预训练和微调设置,而ManagerTower显著提高了下游性能,特别是在VQAv2 Test-Std上取得了79.15%的准确率。
这进一步表明,在所有其他因素固定的情况下,与为METER引入Bridge的BridgeTower相比, ManagerTower通过精心设计的Manager,能够更有效地利用不同层次的单模态语义知识。
值得注意的是,ManagerTower不仅超过了许多在4M数据上预训练的base模型,而且还超过了一些用更多数据或参数训练的大模型。
5. 可视化结果¶
我们通过对VQAv2验证集上的所有样本,可视化每个跨模态层的文本或视觉Manager的平均聚合权重,来深入研究Manager是如何聚合Insight的。

上图展示了SAUE Manager的聚合权重分布。其中,X轴表示单模态专家的编号,图例表示跨模态层的编号。 不管是文本行还是视觉行,不同跨模态层的SAUE Manager都有类似的渐进趋势,这与我们对SAUE Manager的单模态聚合表示之间的余弦相似度的观察是一致的。

有趣的是,对于AAUE Manager来说,Manager生成的聚合权重分布与BridgeTower中人为指定的独热分布完全不同,而且有两个不同的趋势:
- 在垂直方向上,文本和视觉Manager之间存在着明显的差异。
- 在水平方向上,无论是文本Manager还是视觉Manager,他们在不同的跨模态层都表现出非常不同的聚合权重分布。
这有力地证明了AAUE Manager能够自适应地利用不同层次的单模态语义知识进行全面的跨模态表示学习。
6. 结论¶
在本文中,我们提出了ManagerTower,它通过在每个跨模态层中引入Manager,从而自适应地聚合不同层次的预训练单模态专家的Insight,针对不同样本中的不同令牌,灵活地生成不同的聚合权重,促进更全面的跨模态对齐和融合。 通过交叉注意力机制融合之前跨模态层的输出表示,从而得到跨模态融合查询,进一步帮助Manager正确聚合当前跨模态层所需的单模态语义知识。
仅利用400万张独立图像进行视觉语言预训练,ManagerTower在各种下游的视觉语言任务上取得了卓越的表现。尤其是,METER、BridgeTower和ManagerTower使用相同的预训练和微调设置,而ManagerTower显著提高了下游性能,特别是在VQAv2 Test-Std上取得了79.15%的准确率,在Flickr30K上的取得了86.56%IR@1和95.64%TR@1的效果。
7. 附录¶
我们在附录中给出了更加丰富的实验结果与分析,包括:
- ManagerTower和BridgeTower模型的参数量、计算量、推理时间和下游任务性能的详细比较与分析
- ManagerTower中不同类型的Manager的聚合权重分布的可视化结果
- ManagerTower的预训练和下游任务微调的详细参数配置
- ......
欢迎感兴趣的同学阅读我们的论文。